Replica
[VGG-16] Very Deep Convolutional Networks for Large-Scale Image Recognition
Karen Simonyan, Andrew Zisserman
import torch
import torch.nn as nn
class VGG16(nn.Module):
def __init__(self, num_classes=1000) -> None:
super(VGG16, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(128, 128, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(128, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(256, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return xIntroduction
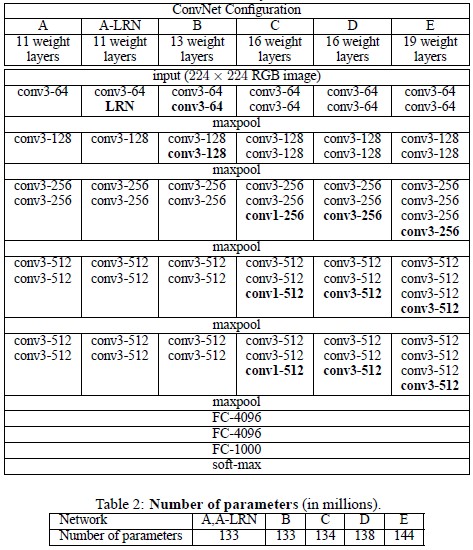
Simonyan and Zisserman, 2014 introduced the importance of depth in the architectural design of the convolutional neural network (CNN). This is achieved by fixing the other parameters of the architecture, and steadily increasing the depth of the network by adding more convolutional layers by using small () convolutional filters (kernel sizes) in all layers.
Architecture
Using smaller kernel sizes allows the use of more ReLU layers, which makes the decision function more discriminative. This also has the benefit of reducing the number of parameters in the network, as a 3-layer convolutional layer () stack has fewer parameters than a single convolutional layer () where is the number of channels.
Max-pooling is performed with a kernel size of 2 and stride of 2.
All hidden layers use ReLU activation functions.
None of the networks except one of the proposed configurations contain Local Response Normalization (LRN) layers, which the authors claim does not improve the performance on the ILSVRC dataset, but leads to increased memory and computational requirements.
The implemented model is configuration D of the proposed architecture.
Training
Waiting for datasets to be downloaded. Will be trained on the ILSVRC 2010 dataset for object classification and ILSVRC 2012 dataset for object localization and object detection.
Results
WIP