Replica
[AlexNet] ImageNet Classification with Deep Convolutional Neural Networks
Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton
import torch
import torch.nn as nn
class AlexNet(nn.Module):
def __init__(self, num_classes=1000) -> None:
super(AlexNet, self).__init__()
self.features = nn.Sequential(
# First layer (96 -> 2x48 in original paper)
nn.Conv2d(3, 96, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.LocalResponseNorm(size=5, alpha=1e-4, beta=0.75, k=2),
nn.MaxPool2d(kernel_size=3, stride=2),
# Second layer (256 -> 2x128 in original paper)
nn.Conv2d(96, 256, kernel_size=5, padding=2, groups=2),
nn.ReLU(inplace=True),
nn.LocalResponseNorm(size=5, alpha=1e-4, beta=0.75, k=2),
nn.MaxPool2d(kernel_size=3, stride=2),
# Third layer
nn.Conv2d(256, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
# Fourth layer
nn.Conv2d(384, 384, kernel_size=3, padding=1, groups=2),
nn.ReLU(inplace=True),
# Fifth layer
nn.Conv2d(384, 256, kernel_size=3, padding=1, groups=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.classifier = nn.Sequential(
nn.Dropout(0.5),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.normal_(m.weight, mean=0, std=0.01)
if m.bias is not None:
# Set bias to 1 for 2nd, 4th, and 5th conv layers
layer_name = m._get_name()
if 'conv2' in layer_name or 'conv4' in layer_name or 'conv5' in layer_name:
nn.init.constant_(m.bias, 1)
else:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
# Use same initialization for all layers
nn.init.normal_(m.weight, mean=0, std=0.01)
# Set bias to 1 for hidden layers, 0 for output layer
if m.out_features != 1000: # Hidden layer
nn.init.constant_(m.bias, 1)
else: # Output layer
nn.init.constant_(m.bias, 0)import os
import torch
import torch.nn as nn
import torch.optim as optim
from pathlib import Path
from tqdm import tqdm
from model import AlexNet
from dataloader import get_dataloaders, PCAColorAugmentation, get_transforms
from torch.amp import autocast, GradScaler
def train_one_epoch(model, criterion, optimizer, train_loader, device, epoch, scaler):
model.train()
running_loss = 0.0
correct = 0
total = 0
pbar = tqdm(train_loader, desc=f'Epoch {epoch}')
for i, (images, labels) in enumerate(pbar):
images = images.to(device, non_blocking=True)
labels = labels.to(device, non_blocking=True)
optimizer.zero_grad(set_to_none=True)
with autocast(device_type=device.type):
outputs = model(images)
loss = criterion(outputs, labels)
scaler.scale(loss).backward()
scaler.unscale_(optimizer)
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=2.0)
scaler.step(optimizer)
scaler.update()
# Update metrics
running_loss += loss.item()
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
if i % 50 == 0:
pbar.set_postfix({
'loss': f'{running_loss/(i+1):.3f}',
'acc': f'{100.*correct/total:.2f}%',
'gpu': f'{torch.cuda.memory_allocated()/1024**3:.1f}GB'
})
return running_loss / len(train_loader), 100. * correct / total
def validate(model, criterion, val_loader, device):
model.eval()
running_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for images, labels in tqdm(val_loader, desc='Validation'):
# images shape should be [batch_size, n_crops, channels, height, width]
if len(images.shape) < 5:
images = images.unsqueeze(0)
batch_size, n_crops = images.shape[:2]
# Reshape images to process all crops at once
images = images.view(-1, *images.shape[2:]) # [batch_size * n_crops, channels, height, width]
images = images.to(device, non_blocking=True)
labels = labels.to(device, non_blocking=True)
# Forward pass
outputs = model(images)
# Average predictions across the crops
outputs = outputs.view(batch_size, n_crops, -1)
outputs = outputs.mean(1) # Average over crops
loss = criterion(outputs, labels)
running_loss += loss.item()
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
return running_loss / len(val_loader), 100. * correct / total
def main():
# Set device
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f'Using device: {device}')
if torch.cuda.is_available():
print(f'GPU: {torch.cuda.get_device_name()}')
# Create model directory
save_dir = Path('checkpoints/alexnet')
save_dir.mkdir(exist_ok=True, parents=True)
# Initialize model
model = AlexNet(num_classes=1000)
model = model.to(device)
if torch.cuda.device_count() > 1:
print(f"Using {torch.cuda.device_count()} GPUs!")
model = nn.DataParallel(model)
torch.cuda.empty_cache()
# Training parameters
num_epochs = 200
batch_size = 128 * max(2, torch.cuda.device_count())
base_lr = 0.01
# Initialize gradient scaler
scaler = GradScaler()
train_loader, _ = get_dataloaders(
root_dir='data/ILSVRC2010',
batch_size=128,
num_workers=12
)
# Compute PCA using a subset of the training data
color_augmentation = PCAColorAugmentation(dataloader=train_loader)
# Now get the transforms including PCAColorAugmentation
train_transform = get_transforms(
color_augmentation=color_augmentation,
is_training=True,
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
# Get dataloaders
train_loader, val_loader = get_dataloaders(
batch_size=batch_size,
num_workers=12
)
train_loader.dataset.transform = train_transform
print(f"\nDataset sizes:")
print(f"Training: {len(train_loader.dataset)} images")
print(f"Validation: {len(val_loader.dataset)} images")
print(f"Batch size: {batch_size}")
print(f"Steps per epoch: {len(train_loader)}")
criterion = nn.CrossEntropyLoss().to(device)
# Optimizer settings from paper
optimizer = optim.SGD(
model.parameters(),
lr=base_lr,
momentum=0.9,
weight_decay=0.0005
)
# Learning rate scheduler
scheduler = optim.lr_scheduler.StepLR(
optimizer,
step_size=30,
gamma=0.1
)
# Training loop
best_acc = 0.0
for epoch in range(num_epochs):
print(f"\nEpoch {epoch+1}/{num_epochs}")
print("-" * 20)
# Training phase
train_loss, train_acc = train_one_epoch(
model, criterion, optimizer, train_loader, device, epoch, scaler
)
# Validation phase
val_loss, val_acc = validate(model, criterion, val_loader, device)
# Update learning rate
scheduler.step(val_acc)
# Print epoch summary
print(f"\nEpoch {epoch+1} Summary:")
print(f"Train - Loss: {train_loss:.4f}, Acc: {train_acc:.2f}%")
print(f"Val - Loss: {val_loss:.4f}, Acc: {val_acc:.2f}%")
print(f'Learning rate: {optimizer.param_groups[0]["lr"]:.6f}')
print(f'GPU Memory: {torch.cuda.memory_allocated()/1024**3:.1f}GB')
# Save best model
if val_acc > best_acc:
best_acc = val_acc
print(f"\nNew best accuracy: {val_acc:.2f}%")
torch.save({
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'scheduler_state_dict': scheduler.state_dict(),
'train_loss': train_loss,
'train_acc': train_acc,
'val_loss': val_loss,
'val_acc': val_acc,
'scaler_state_dict': scaler.state_dict(),
}, save_dir / 'best_model.pth')
# Save regular checkpoint every 5 epochs
if (epoch + 1) % 5 == 0:
torch.save({
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'scheduler_state_dict': scheduler.state_dict(),
'train_loss': train_loss,
'train_acc': train_acc,
'val_loss': val_loss,
'val_acc': val_acc,
'scaler_state_dict': scaler.state_dict(),
}, save_dir / f'checkpoint_epoch_{epoch+1}.pth')
torch.cuda.empty_cache()
if __name__ == '__main__':
main()from collections import Counter
from torch.utils.data import Dataset, DataLoader
import torch
from pathlib import Path
import scipy.io as sio
from PIL import Image
from torchvision import transforms
from typing import Optional, Tuple
import numpy as np
from tqdm import tqdm
def compute_mean_std(batch_size=128, num_workers=4):
transform = transforms.Compose([
transforms.Resize((256, 256)), # Fixed size for both dimensions
transforms.ToTensor()
])
dataset = ILSVRC2010Dataset(
root_dir='data/ILSVRC2010',
split='train',
transform=transform
)
loader = DataLoader(
dataset,
batch_size=batch_size,
shuffle=False,
num_workers=num_workers
)
mean = torch.zeros(3)
squared_mean = torch.zeros(3)
total_images = 0
print('Computing mean...')
for batch in tqdm(loader):
images = batch[0]
batch_samples = images.size(0)
images = images.view(batch_samples, images.size(1), -1)
mean += images.mean(2).sum(0)
total_images += batch_samples
mean /= total_images
print('Computing std...')
for batch in tqdm(loader):
images = batch[0]
batch_samples = images.size(0)
images = images.view(batch_samples, images.size(1), -1)
squared_mean += (images.pow(2).mean(2)).sum(0)
squared_mean /= total_images
std = (squared_mean - mean.pow(2)).sqrt()
return mean, std
class ILSVRC2010Dataset(Dataset):
def __init__(self, root_dir, transform=None, split='train'):
self.root_dir = root_dir
self.transform = transform
self.split = split
# Load meta data
meta = sio.loadmat(Path(root_dir, 'devkit', 'data', 'meta.mat'))
self.synsets = meta['synsets']
# Create WNID to label mapping
self.wnid_to_label = {}
for i in range(1000):
synset = self.synsets[i]
wnid = str(synset['WNID'][0][0])
ilsvrc_id = int(synset['ILSVRC2010_ID'][0][0]) - 1
self.wnid_to_label[wnid] = ilsvrc_id
if split == 'train':
self.cache_dir = Path(root_dir) / 'train_cache'
self.images = []
self.image_labels = []
for wnid in self.wnid_to_label:
cache_subdir = self.cache_dir / wnid
if cache_subdir.exists():
synset_images = list(cache_subdir.glob('*.JPEG'))
if synset_images:
self.images.extend(synset_images)
label = self.wnid_to_label[wnid]
self.image_labels.extend([label] * len(synset_images))
elif split == 'val':
self.image_dir = Path(root_dir) / 'val'
gt_path = Path(root_dir) / 'devkit' / 'data' / 'ILSVRC2010_validation_ground_truth.txt'
with open(gt_path, 'r') as f:
self.val_labels = [int(line.strip()) - 1 for line in f]
self.images = sorted(list(self.image_dir.glob('*.JPEG')))
self.image_labels = self.val_labels
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
try:
with Image.open(self.images[idx]) as img:
image = img.convert('RGB')
label = self.image_labels[idx]
if self.transform:
image = self.transform(image)
return image, label
except Exception as e:
print(f"Error loading image {self.images[idx]}: {e}")
new_idx = (idx + 1) % len(self)
return self.__getitem__(new_idx)
class PCAColorAugmentation:
"""
PCA Color augmentation as described in the AlexNet paper.
Pre-computes PCA on a subset of training data for efficiency.
"""
def __init__(self, dataloader: Optional[DataLoader] = None, alphastd: float = 0.1):
self.alphastd = alphastd
self.eigval = None
self.eigvec = None
if dataloader is not None:
self.compute_pca(dataloader)
def compute_pca(self, dataloader: DataLoader):
"""Compute PCA from a sample of training images."""
print("Computing PCA for color augmentation...")
pixels = []
max_samples = 10000 # Limit number of images to process
samples_processed = 0
for images, _ in tqdm(dataloader):
if samples_processed >= max_samples:
break
# Reshape to pixels x channels
batch_size = images.size(0)
images = images.permute(0, 2, 3, 1).reshape(-1, 3)
pixels.append(images)
samples_processed += batch_size
pixels = torch.cat(pixels, dim=0)
# Center the pixel values
mean = pixels.mean(dim=0, keepdim=True)
pixels_centered = pixels - mean
# Compute covariance matrix
cov = torch.mm(pixels_centered.t(), pixels_centered) / (pixels_centered.size(0) - 1)
# Compute eigenvectors and eigenvalues
eigval, eigvec = torch.linalg.eigh(cov)
# Reverse to descending order
eigval = eigval.flip(0)
eigvec = eigvec.flip(1)
self.eigval = eigval
self.eigvec = eigvec
print("PCA computation completed.")
def __call__(self, img: torch.Tensor) -> torch.Tensor:
"""
Apply PCA color augmentation to an image.
Args:
img: Tensor image [C,H,W]
Returns:
Augmented tensor image [C,H,W]
"""
if self.eigval is None or self.eigvec is None:
return img
# Generate random weights
alpha = torch.randn(3, device=img.device) * self.alphastd
# Calculate the color perturbation
rgb = (self.eigvec * alpha.unsqueeze(0)) @ self.eigval.unsqueeze(1)
perturbation = rgb.view(3, 1, 1)
# Apply perturbation
img_aug = img + perturbation.float()
return img_aug
class TenCropWrapper:
"""
Wrapper for validation that performs 10-crop evaluation as in the AlexNet paper.
"""
def __init__(self, mean, std):
self.mean = mean
self.std = std
def _normalize_tensor(self, tensor):
"""Helper method to normalize a tensor using mean and std"""
for t, m, s in zip(tensor, self.mean, self.std):
t.sub_(m).div_(s)
return tensor
def __call__(self, img):
# First resize the image to 256x256
resize_transform = transforms.Resize(256)
img = resize_transform(img)
# Get all 10 crops
crops = transforms.TenCrop(224)(img)
# Convert to tensors and normalize
result = []
for crop in crops:
tensor = transforms.ToTensor()(crop)
tensor = self._normalize_tensor(tensor.clone())
result.append(tensor)
return torch.stack(result)
def get_transforms(color_augmentation: Optional[PCAColorAugmentation] = None,
is_training: bool = True,
mean: Tuple[float, float, float] = (0.485, 0.456, 0.406),
std: Tuple[float, float, float] = (0.229, 0.224, 0.225)) -> transforms.Compose:
"""
Get transforms for training or validation.
"""
if is_training:
transform_list = [
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor()
]
if color_augmentation is not None:
transform_list.append(color_augmentation)
# Normalization should be the last step
transform_list.append(transforms.Normalize(mean=mean, std=std))
return transforms.Compose(transform_list)
else:
return TenCropWrapper(mean=mean, std=std)
def get_dataloaders(root_dir='data/ILSVRC2010', batch_size=128, num_workers=8):
"""
Create and return training and validation dataloaders for ILSVRC2010.
Now includes PCA color augmentation and 10-crop validation.
"""
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
# Create a simple transform to compute PCA
initial_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor()
])
# Create initial dataset for PCA computation
initial_dataset = ILSVRC2010Dataset(
root_dir=root_dir,
split='train',
transform=initial_transform
)
initial_loader = DataLoader(
initial_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=num_workers,
pin_memory=True
)
# Create and compute PCA color augmentation
color_augmentation = PCAColorAugmentation(initial_loader)
# Training transforms with PCA color augmentation
train_transform = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
color_augmentation,
transforms.Normalize(mean=mean, std=std)
])
# Validation transforms with 10-crop
val_transform = TenCropWrapper(mean=mean, std=std)
# Create datasets with final transforms
train_dataset = ILSVRC2010Dataset(
root_dir=root_dir,
split='train',
transform=train_transform
)
val_dataset = ILSVRC2010Dataset(
root_dir=root_dir,
split='val',
transform=val_transform
)
train_loader = DataLoader(
train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=num_workers,
pin_memory=True,
drop_last=True
)
val_loader = DataLoader(
val_dataset,
batch_size=batch_size // 10,
shuffle=False,
num_workers=num_workers,
pin_memory=True
)
return train_loader, val_loader
if __name__ == '__main__':
train_loader, val_loader = get_dataloaders()Introduction
The original breakout convolutional neural network (CNN) introduced by Alex Krizhevsky et al. in 2012, which achieved SOTA top-1 and top-5 error rates of 37.5% and 17.0% on the 2010 ImageNet dataset respectively. This model featured a much deeper neural network architecture, the use of ReLU (Rectified Linear Unit) activation functions, and a dropout regularization technique to prevent overfitting.
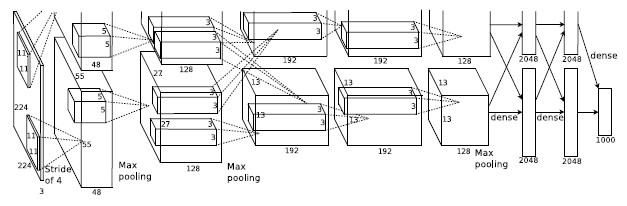
Architecture
ReLU activations () are used in favor of the standard tanh activation function (), as the ReLU-based models are able to be trained several times faster than the tanh-based models.
Local response normalization is given by the expression where the hyper-parameters are set as and . Using response normalization reduces the top-1 and top-5 error rates by 1.4% and 1.2% respectively.
Pooling layers are used to summarize the feature maps of the convolutional layers. A pooling layer can be thought of as consisting of a grid of pooling units spaced pixels apart, each summarizing a neighborhood of size centered at the grid unit's location. Overlapping pooling is used with and , which reduces the top-1 and top-5 error rates by 0.4% and 0.3% respectively.
Reponse normalization layers follow the first and second convolutional layers, and are followed by a pooling layer. The fifth convolutional layer is also followed by a max-pooling layer.
Training
This model was trained using single GPU (3070) rather than the original paper's dual GTX 580 setup on the ILSVRC 2010 dataset for object classification. Modern GPU architecture eliminates the need for the original paper's custom GPU memory management and model splitting.
Epoch 90:
- Train - Loss: 3.0638, Acc: 36.85%
- Val - Loss: 2.6418, Acc: 43.31%
- Learning rate: 0.000100
- GPU Memory: 0.7GB
Results
The current implementation shows significantly lower top-1 performance compared to the original paper: 43.31% validation accuracy (56.69% error rate) vs. 62.5% accuracy (37.5% error rate). I have several guesses as to why there's a ~19% accuracy gap:
- Usage of a single GPU, whereas the dual-GPUs may have acted as an ensemble of models to learn the different features of the dataset
- Original implementation used 10-crop evaluation at test time which typically provides 1-2% improvement
- Poor RNG for the initialisation of the weights